你必须要了解的Transformer
LLM大模型,最重要的就是了解Transformer!!!论文:Attention Is All You Need Transformer是首个完全基于自注意力机制、不使用RNN或CNN的序列建模模型,编码器-解码器架构目的是机器翻译。 每层总计算复杂度下降,并行计算能力大幅提升充分利用硬件,模型内部学习长距离依赖的能力大幅提升。
一个标准的Transformer Block
Layer Norm层归一化 + MSA多头自注意力 + Layer Norm + FFN前馈神经网络 + Residual残差连接
⭐Embedding
Embedding 的核心是将离散ID映射为低维稠密的连续向量,并通过训练让向量捕捉符号的语义/特征信息。核心组成如下:
| 组成部分 | 作用 | 说明 |
|---|---|---|
| 词汇表/符号表 | 定义所有可能的离散输入(如词、字、类别ID) | 大小为$V$(词汇表大小),每个符号对应唯一整数ID,词汇分为基础词、字词片段和特殊符号,词汇表常存储为文本文件,每行一个词,行号就是ID |
| 嵌入矩阵(核心) | 存储每个符号对应的向量 | 形状为$V \times d_{\text{model}}$,$d_{\text{model}}$ 是向量维度;矩阵参数可通过反向传播优化 |
| 查找层(索引层) | 根据输入ID,从嵌入矩阵中取出对应向量 | 本质是整数索引操作,无额外参数;PyTorch中 nn.Embedding、TensorFlow中 tf.keras.layers.Embedding实现 |
- 输入:离散符号的整数ID序列 $\boldsymbol{x} = [x_1, x_2, ..., x_T]$,$x_i \in {0, 1, ..., V-1}$
- 嵌入矩阵:$\boldsymbol{E} \in \mathbb{R}^{V \times d_{\text{model}}}$
- 输出:嵌入向量序列 $\boldsymbol{h} = [\boldsymbol{E}[x_1], \boldsymbol{E}[x_2], ..., \boldsymbol{E}[x_T]]$,$\boldsymbol{h} \in \mathbb{R}^{T \times d_{\text{model}}}$ 示例:词汇表大小 $V=10000$,嵌入维度 $d_{\text{model}}=128$,则嵌入矩阵为 $10000 \times 128$ 的张量;输入词ID=5,输出为矩阵第5行的128维向量。
词汇表文件
[PAD]
[UNK]
[CLS]
[SEP]
[MASK]
the
a
hello
##llo
world
##ld
emb
##ed
##ding
Embedding训练机制
- 初始化:嵌入矩阵通常用均匀分布/正态分布随机初始化
- 优化:通过反向传播更新矩阵参数;损失函数(如分类任务的交叉熵、生成任务的负对数似然)会引导向量学习——语义相近的符号,其嵌入向量的余弦相似度更高
- 示例:训练后,“苹果”和“香蕉”的向量距离,会比“苹果”和“电脑”的距离更近
Embedding训练优化
- 预训练嵌入:如Word2Vec、GloVe、FastText,可直接加载预训练矩阵作为初始化,加速模型收敛
- 微调:预训练嵌入加载后,可继续在下游任务中微调参数,适配任务场景
位置编码
Positional Encoding。在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。 位置编码通过添加位置信息,让模型区分词元的顺序。 固定位置编码:基于三角函数
-
公式:矩阵第 i 行、第 2j 列和 2j+1 列上的元素(偶数维度用正弦,奇数维度用余弦):
-
$$ p_{i, 2j} = \sin(i / 10000^{2j/d}), \quad p_{i, 2j+1} = \cos(i / 10000^{2j/d}) $$
- 不同维度的频率不同,低维度频率高(变化快),高维度频率低(变化慢)。
- 位置 i+δ 的编码可通过 i 的编码线性变换得到,隐含相对位置信息。
- 为什么不直接用数字?无法表达相对位置的统一模式、数值范围失控、泛化能力差。
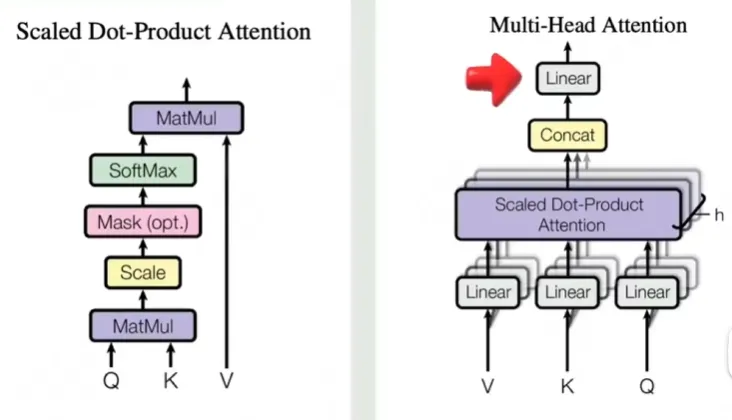
⭐多头自注意力
Multi-Head Self-Attention,核心思想是让模型在同一层中使用多个独立的“自注意力头”,从不同子空间中提取信息,提升模型捕捉复杂关系的能力
自注意力:让序列中的词元“互相关注”
Self-Attention 自注意力是一种特殊的注意力机制,输入的查询、键、值都来自同一组数据(比如同一个句子中的词元)。每个词元都充当查询,同时关注序列中的所有词元(包括自己),计算彼此的相关性,从而生成新的表示。
- 例子:句子“I like apple”中,“like”作为查询,会同时关注“I”、“like”、“apple”,根据相关性分配权重,生成更全面的表示。
与卷积、循环网络的对比
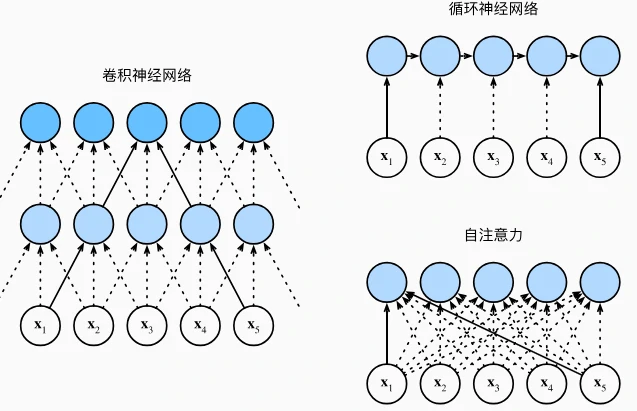
| 架构 | 计算复杂度 | 并行能力 | 最长路径长度 | 适合场景 |
|---|---|---|---|---|
| 卷积网络 | O(kn d²) | 高(层内并行) | O(n/k) | 局部特征提取(如图像) |
| 循环网络 | O(n d²) | 低(顺序操作) | O(n) | 长序列(如语音、文本) |
| 自注意力 | O(n² d) | 高(全并行) | O(1) | 长距离依赖(如机器翻译) |
⭐MSA原理
- 步骤 1:线性变换:将输入的查询(Query)、键(Key)、值(Value)通过不同的线性层(全连接层)投影到多个子空间变成多头。例如,假设输入维度是 100,分成 5 个头,每个头的维度变为 20(100/5=20)。
- 公式:$\text{Query}_i = W_i^Q \cdot \text{Query}, \quad \text{Key}_i = W_i^K \cdot \text{Key}, \quad \text{Value}_i = W_i^V \cdot \text{Value}$ (每个头有独立的投影矩阵$W_i^Q, W_i^K, W_i^V$,且总输入维度需能被头数整除)
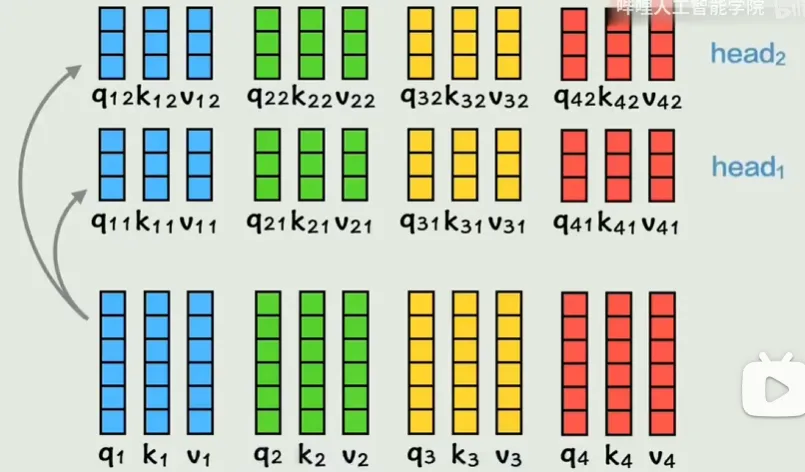
- 公式:$\text{Query}_i = W_i^Q \cdot \text{Query}, \quad \text{Key}_i = W_i^K \cdot \text{Key}, \quad \text{Value}_i = W_i^V \cdot \text{Value}$ (每个头有独立的投影矩阵$W_i^Q, W_i^K, W_i^V$,且总输入维度需能被头数整除)
- 步骤 2:并行计算注意力:每个头独立计算注意力权重,得到各自的输出,每个头对应一个独特的语义子空间(捕捉不同类型的语义关联,如语法依赖、语义相似性)。
计算逻辑:对每个头的 $Query_i$ 和 $Key_i$ 计算点积相似度,经缩放(除以 $\sqrt{d_k}$,$d_k$ 为 Key 维度)和 Softmax 归一化得到权重,再用权重对 $Value_i$ 加权求和。
- 步骤 3:结果拼接与变换:将各头的输出按维度拼接,恢复至原输入维度,再通过一个线性层融合多头部信息,得到最终的自注意力输出。
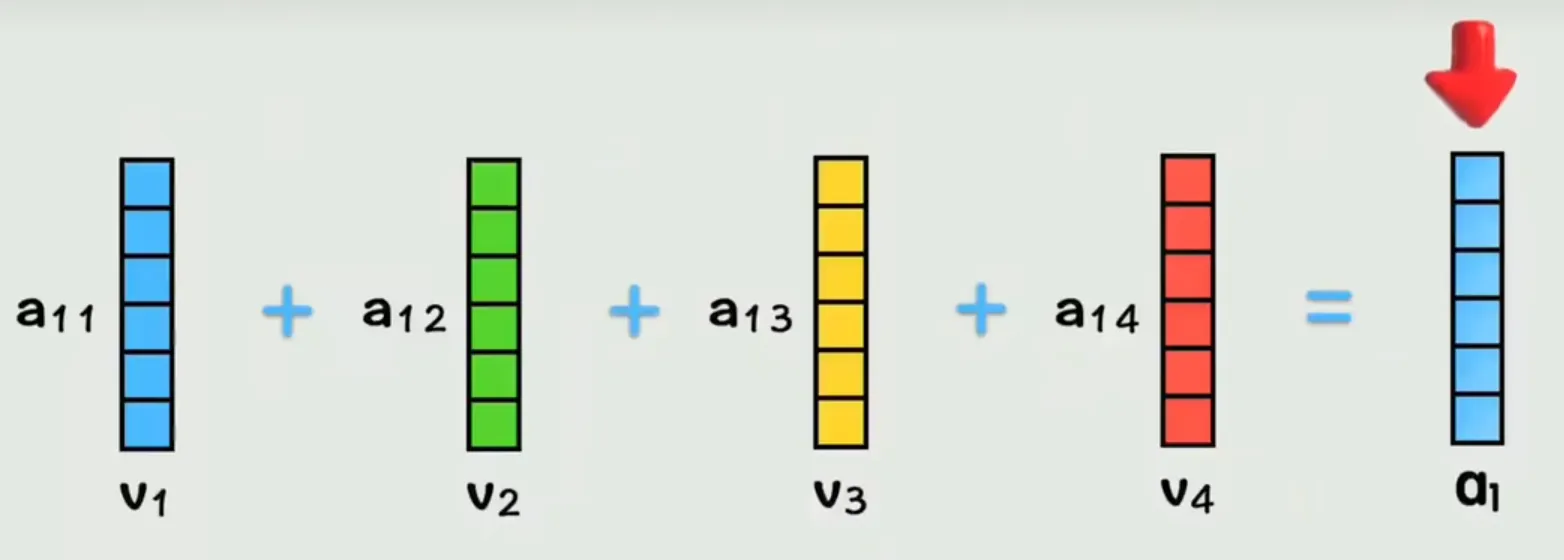
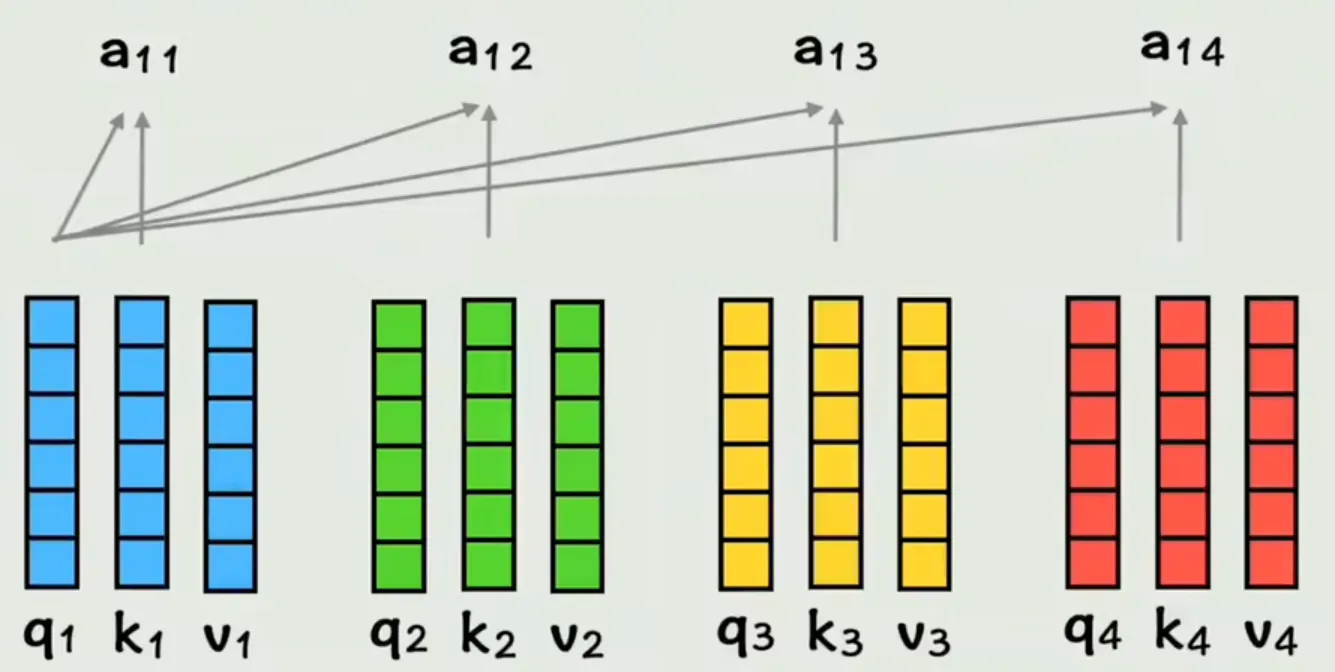
一句话理解文本句子里的 Q、K、V
比如输入句子:我 爱 吃 苹果(4 个词,每个词是一个向量)
- 对「我」这个词来说:
- Q:「我」作为当前词,用于主动查询上下文里与自己相关的词(比如动作、对象)。
- K:句子里每个词的 匹配特征(用于和 Q 计算相似度,判断关联程度)。
- V:句子里每个词的 实际语义内容(最终要加权融合的信息)。
- 注意力计算:「我」的 Q 与所有词的 K 做点积运算,经缩放和 Softmax 得到注意力权重(比如「苹果」权重最高),再用权重对 V 加权求和,得到「我」融合上下文后的新向量。
- 补充:用 $q_1$(「我」的 Query 向量)匹配所有词的 $k$(Key 向量)的操作是点积,而非相加;得到的 $a_{11},a_{12},a_{13}$ 是原始相似度,经 Softmax 后才是归一化的注意力权重。 最后每个词的向量都带全局上下文,内存发出了救命!!
单头与多头注意力机制结构对比
对于不同的注意力头,各个头的参数最初是随机赋值的,在训练过程中通常会朝着不同的方向演变。真实的 NLP 任务(如翻译、文本分类)的损失函数,对不同类型的特征都有需求 —— 单一特征模式无法最小化损失,模型必须让多头分工才能达到最优性能。
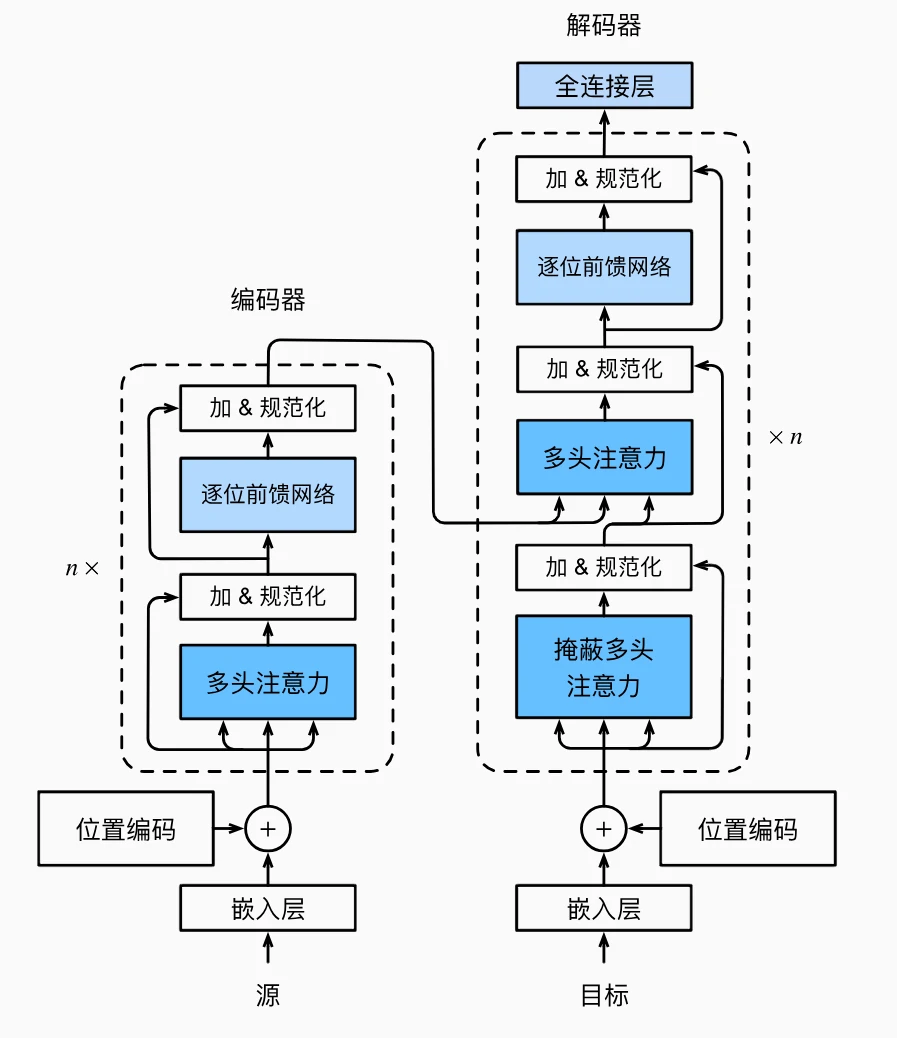
编码器(Encoder)
- 作用:将输入序列(如英语句子)转换成隐藏层表示。
- 结构:由多个相同的编码器块(Encoder Block)堆叠而成,每个块包含:
- 多头自注意力层(Multi-Head Self-Attention):每个词元同时作为查询、键和值,计算自身与其他所有词元的注意力权重,捕捉全局依赖关系。
- 前馈神经网络(Position-wise Feed-Forward Network):对每个词元的表示进行非线性变换,增强模型表达能力。
- 残差连接(Residual Connection)和层规范化(Layer Normalization):解决深度网络训练难题,稳定训练过程。
- 位置编码(Positional Encoding):由于自注意力不包含顺序信息,通过正弦和余弦函数为每个词元添加位置编码,区分序列中的位置关系。
解码器(Decoder)
- 作用:根据编码器输出和已生成的词元,逐步生成目标序列(如法语翻译)。
- 结构:由多个解码器块(Decoder Block)堆叠而成,每个块包含:
- 掩蔽多头自注意力层(Masked Multi-Head Self-Attention):确保解码时只能关注已生成的词元(自回归属性),避免信息泄露。
- 编码器-解码器注意力层(Encoder-Decoder Attention):查询来自解码器当前输出,键和值来自编码器输出,建立输入与输出之间的关联。
- 前馈神经网络、残差连接和层规范化:与编码器类似。
残差连接
将某一层的输入与该层经过处理后的输出进行逐元素相加,再传入后续的层(通常是 Layer Normalization 层)。防止某层很烂导致整体很差。