LLM微调理论知识—寒枫
SFT、RLHF、RAG
SFT
Supervised Fine-Tuning有监督微调,提到 “微调” 时通常是指有监督微调,通过提供人工标注的高质量指令 - 响应数据,进一步训练预训练基座模型,让模型精准适配特定领域 / 任务,对齐基础指令遵循能力。
微调算法分类
全参数微调(Full Fine-Tuning) 更新模型所有参数,性能上限最高,适配性强;算力成本极高;数据不足时极易过拟合。 部分参数微调(Partial Fine-Tuning) 仅更新模型特定层 / 模块参数(如 Transformer 的 attention 层),大幅降低算力与存储成本;过拟合风险低;迭代速度快 代表算法:LoRA(最主流)、Adapter、IA3
RLHF
Reinforcement Learning from Human Feedback,基于人类反馈的强化学习 核心目标:通过人类偏好信号,让模型生成更符合人类价值观、更有用、无害的内容;标准流程为 SFT 基座模型 → 收集人类偏好数据 → 训练奖励模型 RM → 强化学习优化策略模型
- PPO(Proximal Policy Optimization)
- 核心思想:渐进式调整模型策略,通过奖励信号(RM 输出分数)优化,同时用KL 散度约束防止模型输出偏离原 SFT 模型太远(避免灾难性遗忘)
- 特点:调整幅度小、稳定可控,是 RLHF 的核心算法
-
- 监督微调 (SFT):用高质量的“指令-回答”数据微调预训练模型,让它先学会基本指令跟随。 2. 训练奖励模型 (RM):收集偏好数据(如对同一问题,人工标注A回答比B好),然后训练一个独立的奖励模型,给输出打分。 3. PPO 强化学习:用奖励模型作为“裁判”,模型生成回答得高分则奖励,低分则惩罚,逐步调整参数。
- DPO(Direct Preference Optimization)
- 核心思想:跳过奖励模型与 PPO 的复杂流程,直接用人类对比偏好数据(A/B 选项优劣)优化生成模型。直接微调:用特殊损失函数,提高好回答概率,降低坏回答概率,像 SFT 一样简单。
- 特点:调整幅度大、训练流程简化、算力成本低;适合快速对齐人类偏好
注意:对比学习是无监督 / 自监督学习的一种,通过拉近正样本、推远负样本优化模型;RLHF 是强化学习框架,需先训练奖励模型(拟合人类偏好),再通过强化学习优化模型策略。
Align(对齐)
-
定义:Align 是指将模型的输出与人类的期望、价值观、道德标准等进行对齐,确保模型生成的内容不仅在技术上正确,还能在伦理和社会层面上符合人类的需求。
-
Align 通常结合 SFT 和 RLHF 来实现
RAG(Retrieval-Augmented Generation)检索增强生成
核心目标:将外部知识库的信息融入生成过程,解决大模型知识过时、幻觉、领域知识不足的问题
核心流程: 1. 数据预处理:文档拆分、向量化(通过 Embedding 模型生成向量) 2. 向量存储:将向量存入向量数据库(如 Pinecone、Milvus、Chroma) 3. 检索:用户提问向量化后,在向量库中检索最相关的 Top-K 文档片段 4. 生成:将提问 + 检索结果拼接为 Prompt,送入大模型生成答案
核心优点:无需微调大模型即可更新知识;降低幻觉;成本低 核心优化点:文档切分策略、Embedding 模型选择、向量数据库检索精度、Prompt 工程
超参搜索
手动设置超参效率低,以下为工业界主流超参优化方法,核心是在超参空间中高效找到最优组合
| 方法 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|
| 网格搜索(Grid Search) | 遍历超参候选值的所有组合,交叉验证评估 | 简单直观、结果稳定 | 维度灾难,高维场景算力成本极高 |
| 随机搜索(Random Search) | 在超参空间随机采样,评估后保留最优 | 高维场景效率优于网格搜索 | 结果有随机性,需足够采样次数 |
| 贝叶斯优化 | 用概率模型(如高斯过程)建模超参-性能关系,优先评估潜在最优组合 | 自适应聚焦最优区域,适合高算力成本场景 | 实现复杂,对初始样本质量敏感 |
| 启发式搜索(遗传算法/粒子群) | 借鉴生物进化/群体智能,通过选择、交叉、变异迭代优化 | 适合非凸、复杂超参空间,鲁棒性强 | 计算成本高,收敛速度可能较慢 |
微调算法
Linear Probe线性探针
Linear Probe(线性探针) 是一种用于评估预训练模型(尤其是表示学习模型)学到的特征质量的方法。它的核心思想是:冻结冻结预训练模型的参数,仅在其输出的特征之上训练一个简单的线性分类器(或回归器),通过该线性模型的性能来衡量预训练特征的判别能力。
LoRA
LoRA 开山论文:LORA: LOW-RANK ADAPTATION OF LARGE LAN GUAGE MODELS,2021 年 Microsoft Research 提出,首次提出了通过低秩矩阵分解的方式来进行部分参数微调,极大推动了 AI 技术在多行业的广泛落地应用:
大模型的权重更新矩阵本质具有低秩特性(即高维更新可由低维矩阵近似)。矩阵的秩(Rank of a matrix)是指矩阵中线性无关的行或列的最大数量。简单来说它能反映矩阵所包含的有效信息量。通过将大矩阵分解为两个小矩阵的乘积,显著减少参数量。LoRA 训练结束后通常需要进行权重合并(升维)。 核心操作:在 Transformer 的 attention 层中插入 LoRA 模块;训练时冻结原模型参数,仅更新 LoRA 的 A、B 矩阵;训练后合并 LoRA 权重与原权重(升维)
QLoRA
LoRA 的量化版本,面向低资源场景,- 将基座模型量化为 4-bit/8-bit,同时结合 LoRA 低秩微调,在极小显存下实现高效微调
- 核心操作:
- 模型量化:用 NF4(NormalFloat4)量化方案压缩模型权重
- 冻结量化模型参数,插入 LoRA 模块并使用双量化、分页优化等技术减少显存占用
- 训练 LoRA 模块,训练后合并权重
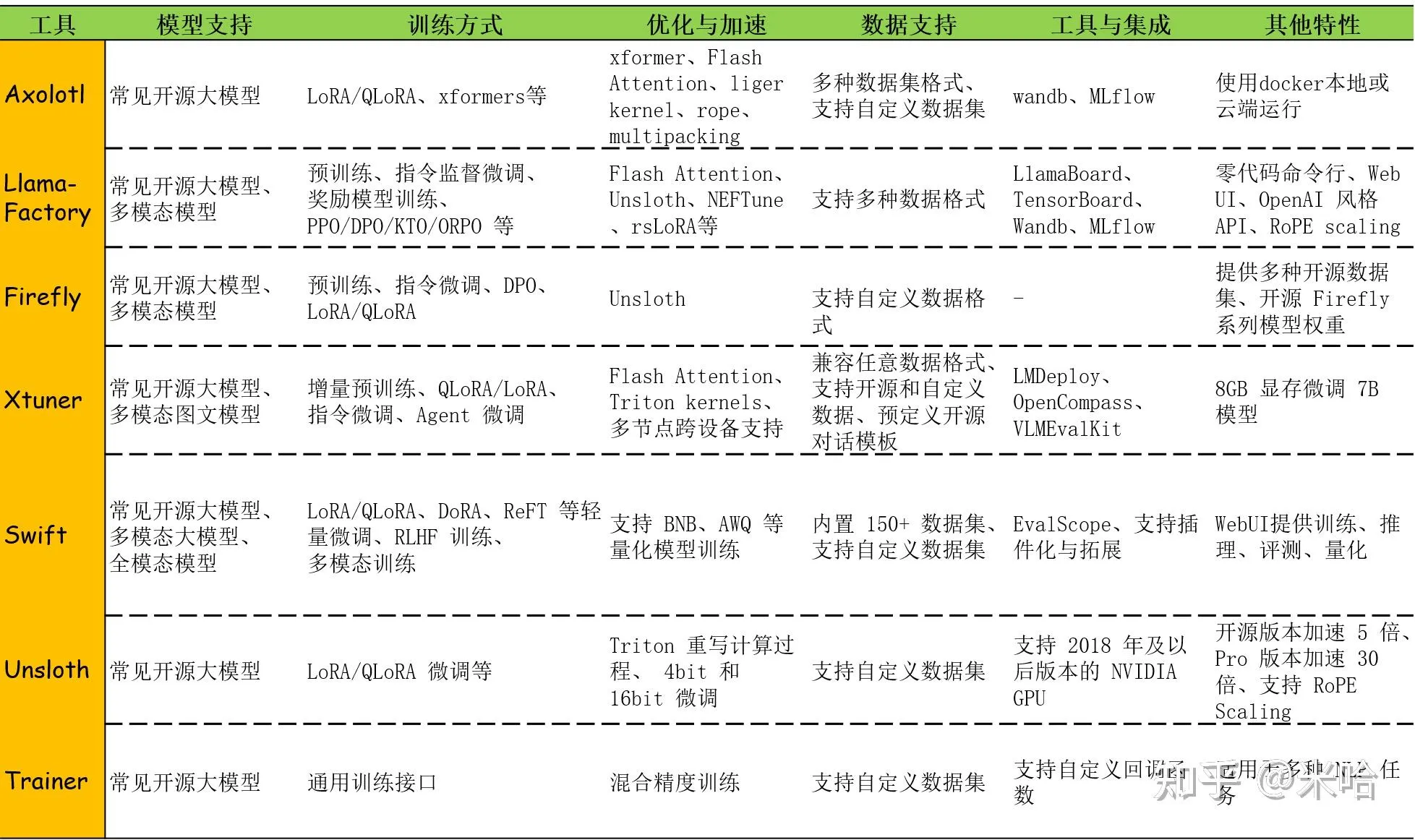
微调常见实现框架
- Llama-Factory:由国内北航开源的低代码大模型训练框架,可以实现零代码微调
- transformers.Trainer:由 Hugging Face 提供的高层 API,适用于各种 NLP 任务的微调,提供标准化的训练流程和多种监控工具,适合需要更多定制化的场景,尤其在部署和生产环境中表现出色