HappyLLM笔记--寒枫
非常好的入门教程:datawhalechina/happy-llm: 📚 从零开始的大语言模型原理与实践教程
前言
LLM(Large Language Model,LLM) 其实是 NLP(Natural Language Processing,NLP) 领域经典研究方法预训练语言模型(Pretrain Language Model,PLM)的一种衍生成果。 经典的 PLM,包括 Encoder-Only、Encoder-Decoder 和 Decoder-Only 三种架构。 主流的 LLM 训练框架 Transformers。
第一章 NLP 基础概念
NLP 任务
不限于中文分词、子词切分、词性标注、文本分类、实体识别、关系抽取、文本摘要、机器翻译以及自动问答系统的开发。
中文分词
中文分词(Chinese Word Segmentation, CWS)是 NLP 领域中的一个基础任务。在处理中文文本时,由于中文语言的特点,词与词之间没有像英文那样的明显分隔(如空格),所以无法直接通过空格来确定词的边界。因此,中文分词成为了中文文本处理的首要步骤,其目的是将连续的中文文本切分成有意义的词汇序列。
子词切分
子词切分(Subword Segmentation)是 NLP 领域中的一种常见的文本预处理技术,旨在将词汇进一步分解为更小的单位,
词性标注
词性标注(Part-of-Speech Tagging,POS Tagging)是 NLP 领域中的一项基础任务,它的目标是为文本中的每个单词分配一个词性标签,如名词、动词、形容词等。这个过程通常基于预先定义的词性标签集。词性标注通常依赖于机器学习模型,如隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场(Conditional Random Field,CRF)或者基于深度学习的循环神经网络 RNN 和长短时记忆网络 LSTM 等。这些模型通过学习大量的标注数据来预测新句子中每个单词的词性。
文本分类
文本分类(Text Classification)是 NLP 领域的一项核心任务,涉及到将给定的文本自动分配到一个或多个预定义的类别中。这项技术广泛应用于各种场景,包括但不限于情感分析、垃圾邮件检测、新闻分类、主题识别等。文本分类的关键在于理解文本的含义和上下文,并基于此将文本映射到特定的类别。文本分类任务的成功关键在于选择合适的特征表示和分类算法,以及拥有高质量的训练数据。随着深度学习技术的发展,使用神经网络进行文本分类已经成为一种趋势。
实体识别
实体识别(Named Entity Recognition, NER),也称为命名实体识别,是 NLP 领域的一个关键任务,旨在自动识别文本中具有特定意义的实体,并将它们分类为预定义的类别,如人名、地点、组织、日期、时间等。实体识别任务对于信息提取、知识图谱构建、问答系统、内容推荐等应用很重要,它能够帮助系统理解文本中的关键元素及其属性。
关系抽取
关系抽取(Relation Extraction)是 NLP 领域中的一项关键任务,它的目标是从文本中识别实体之间的语义关系。
文本摘要
文本摘要(Text Summarization)是 NLP 中的一个重要任务,目的是生成一段简洁准确的摘要,来概括原文的主要内容。根据生成方式的不同,文本摘要可以分为两大类:抽取式摘要(Extractive Summarization,原文拼接)和生成式摘要(Abstractive Summarization,重新组织改写)。
机器翻译
机器翻译(Machine Translation, MT)指使用计算机程序将一种自然语言(源语言)自动翻译成另一种自然语言(目标语言)的过程。
自动问答
自动问答(Automatic Question Answering, QA)是 NLP 领域中的一个高级任务,旨在使计算机能够理解自然语言提出的问题,并根据给定的数据源自动提供准确的答案。自动问答系统的构建涉及多个 NLP 子任务,如信息检索、文本理解、知识表示和推理等。 自动问答大致可分为三类:检索式问答(Retrieval-based QA)、知识库问答(Knowledge-based QA)和社区问答(Community-based QA)。
文本表示的发展历程
文本表示的目的是将人类语言的自然形式转化为计算机可以处理的形式,也就是将文本数据数字化,使计算机能够对文本进行有效的分析和处理。
词向量
向量空间模型(Vector Space Model, VSM)是 NLP 领域中一个基础且强大的文本表示方法,最早由哈佛大学 Salton 提出。向量空间模型通过将文本(包括单词、句子、段落或整个文档)转换为高维空间中的向量来实现文本的数学化表示。在这个模型中,每个维度代表一个特征项(例如,字、词、词组或短语),而向量中的每个元素值代表该特征项在文本中的权重,这种权重通过特定的计算公式(如词频 TF、逆文档频率 TF-IDF 等)来确定,反映了特征项在文本中的重要程度。
向量空间模型最主要的是数据稀疏性和维数灾难问题,因为特征项数量庞大导致向量维度极高,同时多数元素值为零。此外,由于模型基于特征项之间的独立性假设,忽略了文本中的结构信息,如词序和上下文信息,限制了模型的表现力。特征项的选择和权重计算方法的不足也是向量空间模型需要解决的问题。
N-gram 语言模型
N-gram 模型是 NLP 领域中一种基于统计的语言模型,广泛应用于语音识别、手写识别、拼写纠错、机器翻译和搜索引擎等众多任务。N-gram 模型的核心思想是基于马尔可夫假设,即一个词的出现概率仅依赖于它前面的 N-1 个词。这里的 N 代表连续出现单词的数量,可以是任意正整数。例如,当 N=1 时,模型称为 unigram,仅考虑单个词的概率;当 N=2 时,称为 bigram,考虑前一个词来估计当前词的概率;当 N=3 时,称为 trigram,考虑前两个词来估计第三个词的概率,以此类推 N-gram。 非常简单易用,但当 N 较大时,会出现数据稀疏性问题。模型的参数空间会急剧增大,相同的 N-gram 序列出现的概率变得非常低,导致模型无法有效学习,模型泛化能力下降。此外,N-gram 模型忽略了词之间的范围依赖关系,无法捕捉到句子中的复杂结构和语义信息。
Word2Vec
Word2Vec 是一种流行的词嵌入(Word Embedding)技术。它是一种基于神经网络 NNLM 的语言模型,旨在通过学习词与词之间的上下文关系来生成词的密集向量表示。Word2Vec 的核心思想是利用词在文本中的上下文信息来捕捉词之间的语义关系,从而使得语义相似或相关的词在向量空间中距离较近。
Word2Vec 模型主要有两种架构:连续词袋模型 CBOW(Continuous Bag of Words)是根据目标词上下文中的词对应的词向量, 计算并输出目标词的向量表示;Skip-Gram 模型与 CBOW 模型相反, 是利用目标词的向量表示计算上下文中的词向量. 实践验证 CBOW 适用于小型数据集, 而 Skip-Gram 在大型语料中表现更好。
相比于传统的高维稀疏表示(如 One-Hot 编码),Word2Vec 生成的是低维(通常几百维)的密集向量,有助于减少计算复杂度和存储需求。Word2Vec 模型能够捕捉到词与词之间的语义关系,比如”国王“和“王后”在向量空间中的位置会比较接近,因为在大量文本中,它们通常会出现在相似的上下文中。Word2Vec 模型也可以很好的泛化到未见过的词,因为它是基于上下文信息学习的,而不是基于词典。但由于 CBOW/Skip-Gram 模型是基于局部上下文的,无法捕捉到长距离的依赖关系,缺乏整体的词与词之间的关系,因此在一些复杂的语义任务上表现不佳。
ELMo
ELMo(Embeddings from Language Models)即预训练词嵌入模型,它彻底改变了传统静态词嵌入的局限性,开创了 “动态词嵌入” 的先河。首先在大型语料库上训练语言模型,得到词向量模型,然后在特定任务上对模型进行微调,得到更适合该任务的词向量,ELMo 首次将预训练思想引入到词向量的生成中,使用双向 LSTM 结构,能够捕捉到词汇的上下文信息,生成更加丰富和准确的词向量表示。
ELMo 采用典型的两阶段过程: 第 1 个阶段是利用语言模型进行预训练; 第 2 个阶段是在做特定任务时, 从预训练网络中提取对应单词的词向量作为新特征补充到下游任务中。基于 RNN 的 LSTM 模型训练时间长, 特征提取是 ELMo 模型优化和提升的关键。
第二章 Transformer 架构
由于 NLP 任务所需要处理的文本往往是序列,因此专用于处理序列、时序数据的 RNN 往往能够在 NLP 任务上取得最优的效果。事实上,在注意力机制横空出世之前,RNN 以及 RNN 的衍生架构 LSTM 是 NLP 领域当之无愧的霸主。
但 RNN 及 LSTM 虽然具有捕捉时序信息、适合序列生成的优点,却有两个难以弥补的缺陷:
- 序列依序计算的模式能够很好地模拟时序信息,但限制了计算机并行计算的能力。由于序列需要依次输入、依序计算,图形处理器(Graphics Processing Unit,GPU)并行计算的能力受到了极大限制,导致 RNN 为基础架构的模型虽然参数量不算特别大,但计算时间成本却很高;
- RNN 难以捕捉长序列的相关关系。在 RNN 架构中,距离越远的输入之间的关系就越难被捕捉,同时 RNN 需要将整个序列读入内存依次计算,也限制了序列的长度。虽然 LSTM 中通过门机制对此进行了一定优化,但对于较远距离相关关系的捕捉,RNN 依旧是不如人意的。
针对这样的问题,Vaswani 等学者参考了在 CV 领域被提出、被经常融入到 RNN 中使用的注意力机制(Attention)(注意,虽然注意力机制在 NLP 被发扬光大,但其确实是在 CV 领域被提出的),创新性地搭建了完全由注意力机制构成的神经网络——Transformer,也就是大语言模型(Large Language Model,LLM)的鼻祖及核心架构,从而让注意力机制一跃成为深度学习最核心的架构之一。
2.1 Transformer 的核心--注意力机制
注意力机制有三个核心变量:Query(查询值)、Key(键值)和 Value(真值)。 注意力机制的特点是通过计算 Query 与Key的相关性为真值加权求和,从而拟合序列中每个词同其他词的相关关系。
首先,我们有这样一个字典:
{
"apple":10,
"banana":5,
"chair":2
}
此时,字典的键就是注意力机制中的键值 Key,而字典的值就是真值 Value。字典支持我们进行精确的字符串匹配,例如,如果我们想要查找的值也就是查询值 Query 为“apple”,那么我们可以直接通过将 Query 与 Key 做匹配来得到对应的 Value。
但是,如果我们想要匹配的 Query 是一个包含多个 Key 的概念呢?例如,我们想要查找“fruit”,此时,我们应该将 apple 和 banana 都匹配到,但不能匹配到 chair。因此,我们往往会选择将 Key 对应的 Value 进行组合得到最终的 Value。
例如,当我们的 Query 为“fruit”,我们可以分别给三个 Key 赋予如下的权重:
{
"apple":0.6,
"banana":0.4,
"chair":0
}
那么,我们最终查询到的值应该是:
value=0.6∗10+0.4∗5+0∗2=8value=0.6∗10+0.4∗5+0∗2=8
给不同 Key 所赋予的不同权重,就是我们所说的注意力分数,也就是为了查询到 Query,我们应该赋予给每一个 Key 多少注意力。但是,如何针对每一个 Query,计算出对应的注意力分数呢?从直观上讲,我们可以认为 Key 与 Query 相关性越高,则其所应该赋予的注意力权重就越大。但是,我们如何能够找到一个合理的、能够计算出正确的注意力分数的方法呢?
用点积来计算词之间的相似度,再通过一个 Softmax 层将其转化为和为 1 的权重,多个 Query 对应的词向量堆叠在一起,最后将结果做一个放缩,得到注意力机制的核心计算公式。
$$ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{Q \cdot K^T}{\sqrt{d_k}} \right) \cdot V $$
'''注意力计算函数'''
def attention(query, key, value, dropout=None):
'''
args:
query: 查询值矩阵
key: 键值矩阵
value: 真值矩阵
'''
# 获取键向量的维度,键向量的维度和值向量的维度相同
d_k = query.size(-1)
# 计算Q与K的内积并除以根号dk
# transpose——相当于转置
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# Softmax
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# 采样
# 根据计算结果对value进行加权求和
return torch.matmul(p_attn, value), p_attn
自注意力
注意力机制的本质是对两段序列的元素依次进行相似度计算,寻找出一个序列的每个元素对另一个序列的每个元素的相关度,然后基于相关度进行加权,即分配注意力。在 Transformer 的 Encoder 结构中,使用的是 注意力机制的变种 —— 自注意力(self-attention,自注意力)机制。所谓自注意力,即是计算本身序列中每个元素对其他元素的注意力分布。
掩码自注意力
掩码自注意力,即 Mask Self-Attention,是指使用注意力掩码的自注意力机制。掩码的作用是遮蔽一些特定位置的 token,模型在学习的过程中,会忽略掉被遮蔽的 token。
使用注意力掩码的核心动机是让模型只能使用历史信息进行预测而不能看到未来信息。使用注意力机制的 Transformer 模型也是通过类似于 n-gram 的语言模型任务来学习的,也就是对一个文本序列,不断根据之前的 token 来预测下一个 token,直到将整个文本序列补全。
掩码自注意力会生成一串掩码,来遮蔽未来信息。例如,我们待学习的文本序列仍然是 【BOS】I like you【EOS】,我们使用的注意力掩码是【MASK】,Mask 矩阵会是一个上三角矩阵。模型的输入为:
<BOS> 【MASK】【MASK】【MASK】【MASK】
<BOS> I 【MASK】 【MASK】【MASK】
<BOS> I like 【MASK】【MASK】
<BOS> I like you 【MASK】
<BOS> I like you </EOS>
这样实现了并行的语言模型。
多头注意力机制
多头注意力机制(Multi-Head Attention),即同时对一个语料进行多次注意力计算,每次注意力计算都能拟合不同的关系,将最后的多次结果拼接起来作为最后的输出。
注意力头即控制注意力着重关注的地方,即权重分配的方式。
2.2 注意力机制的核心组件--Encoder-Decoder
Seq2Seq
即序列到序列,是一种经典 NLP 任务。具体而言,是指模型输入的是一个自然语言序列 input=(x1,x2,x3...xn) ,输出的是一个可能不等长的自然语言序列 output=(y1,y2,y3...ym)。事实上,Seq2Seq 是 NLP 最经典的任务,几乎所有的 NLP 任务都可以视为 Seq2Seq 任务。
对于 Seq2Seq 任务,一般的思路是对自然语言序列进行编码再解码。所谓编码,就是将输入的自然语言序列通过隐藏层编码成能够表征语义的向量(或矩阵),可以简单理解为更复杂的词向量表示。而解码,就是对输入的自然语言序列编码得到的向量或矩阵通过隐藏层输出,再解码成对应的自然语言目标序列。通过编码再解码,就可以实现 Seq2Seq 任务。
Transformer 由 Encoder 和 Decoder 组成,每一个 Encoder(Decoder)又由 6 个 Encoder(Decoder)Layer 组成。输入源序列会进入 Encoder 进行编码,到 Encoder Layer 的最顶层再将编码结果输出给 Decoder Layer 的每一层,通过 Decoder 解码后就可以得到输出目标序列了。
Encoder 和 Decoder 内部结构
前馈神经网络(Feed Forward Neural Network,下简称 FFN),也就是我每一层的神经元都和上下两层的每一个神经元完全连接的网络结构。每一个 Encoder Layer 都包含一个上文讲的注意力机制和一个前馈神经网络。
层归一化,也就是 Layer Norm,是深度学习中经典的归一化操作。神经网络主流的归一化一般有两种,批归一化(Batch Norm)和层归一化(Layer Norm)。 归一化核心是为了让不同层输入的取值范围或者分布能够比较一致。由于深度神经网络中每一层的输入都是上一层的输出,因此多层传递下,对网络中较高的层,之前的所有神经层的参数变化会导致其输入的分布发生较大的改变。也就是说,随着神经网络参数的更新,各层的输出分布是不相同的,且差异会随着网络深度的增大而增大。但是,需要预测的条件分布始终是相同的,从而也就造成了预测的误差。 因此,在深度神经网络中,往往需要归一化操作,将每一层的输入都归一化成标准正态分布。
由于 Transformer 模型结构较复杂、层数较深, 为了避免模型退化,Transformer 采用了残差连接的思想来连接每一个子层。残差连接,即下一层的输入不仅是上一层的输出,还包括上一层的输入。残差连接允许最底层信息直接传到最高层,让高层专注于残差的学习。
Encoder
每一个 Encoder Layer 包括一个注意力层和一个前馈神经网络。
class EncoderLayer(nn.Module):
'''Encoder层'''
def __init__(self, args):
super().__init__()
# 一个 Layer 中有两个 LayerNorm,分别在 Attention 之前和 MLP 之前
self.attention_norm = LayerNorm(args.n_embd)
# Encoder 不需要掩码,传入 is_causal=False
self.attention = MultiHeadAttention(args, is_causal=False)
self.fnn_norm = LayerNorm(args.n_embd)
self.feed_forward = MLP(args.dim, args.dim, args.dropout)
def forward(self, x):
# Layer Norm
norm_x = self.attention_norm(x)
# 自注意力
h = x + self.attention.forward(norm_x, norm_x, norm_x)
# 经过前馈神经网络
out = h + self.feed_forward.forward(self.fnn_norm(h))
return out
class Encoder(nn.Module):
'''Encoder 块'''
def __init__(self, args):
super(Encoder, self).__init__()
# 一个 Encoder 由 N 个 Encoder Layer 组成
self.layers = nn.ModuleList([EncoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd)
def forward(self, x):
"分别通过 N 层 Encoder Layer"
for layer in self.layers:
x = layer(x)
return self.norm(x)
Decoder
Decoder 由两个注意力层和一个前馈神经网络组成。第一个注意力层是一个掩码自注意力层,即使用 Mask 的注意力计算,保证每一个 token 只能使用该 token 之前的注意力分数;第二个注意力层是一个多头注意力层,该层将使用第一个注意力层的输出作为 query,使用 Encoder 的输出作为 key 和 value,来计算注意力分数。最后,再经过前馈神经网络。
class DecoderLayer(nn.Module):
'''解码层'''
def __init__(self, args):
super().__init__()
# 一个 Layer 中有三个 LayerNorm,分别在 Mask Attention 之前、Self Attention 之前和 MLP 之前
self.attention_norm_1 = LayerNorm(args.n_embd)
# Decoder 的第一个部分是 Mask Attention,传入 is_causal=True
self.mask_attention = MultiHeadAttention(args, is_causal=True)
self.attention_norm_2 = LayerNorm(args.n_embd)
# Decoder 的第二个部分是 类似于 Encoder 的 Attention,传入 is_causal=False
self.attention = MultiHeadAttention(args, is_causal=False)
self.ffn_norm = LayerNorm(args.n_embd)
# 第三个部分是 MLP
self.feed_forward = MLP(args.dim, args.dim, args.dropout)
def forward(self, x, enc_out):
# Layer Norm
norm_x = self.attention_norm_1(x)
# 掩码自注意力
x = x + self.mask_attention.forward(norm_x, norm_x, norm_x)
# 多头注意力
norm_x = self.attention_norm_2(x)
h = x + self.attention.forward(norm_x, enc_out, enc_out)
# 经过前馈神经网络
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Decoder(nn.Module):
'''解码器'''
def __init__(self, args):
super(Decoder, self).__init__()
# 一个 Decoder 由 N 个 Decoder Layer 组成
self.layers = nn.ModuleList([DecoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd)
def forward(self, x, enc_out):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, enc_out)
return self.norm(x)
2.3 搭建一个 Transformer
Embedding 层
在 NLP 任务中,我们往往需要将自然语言的输入转化为机器可以处理的向量。在深度学习中,承担这个任务的组件就是 Embedding 层。 Embedding 层其实是一个存储固定大小的词典的嵌入向量查找表。也就是说,在输入神经网络之前,我们往往会先让自然语言输入通过分词器 tokenizer,分词器的作用是把自然语言输入切分成 token 并转化成一个固定的 index。
位置编码
注意力机制无法识别位置信息,因此,为使用序列顺序信息,保留序列中的相对位置信息,根据序列中 token 的相对位置对其进行编码,再将位置编码加入词向量编码中。
第三章 预训练语言模型
针对 Encoder、Decoder 的特点,引入 ELMo 的预训练思路,开始出现不同的、对 Transformer 进行优化的思路。3 种核心的模型架构。
3.1 BERT
Encoder-Only 结构模型,全名为 Bidirectional Encoder Representations from Transformers, Google 团队在 2018 年发布的预训练语言模型, Transformer 架构,预训练+微调范式。
模型结构
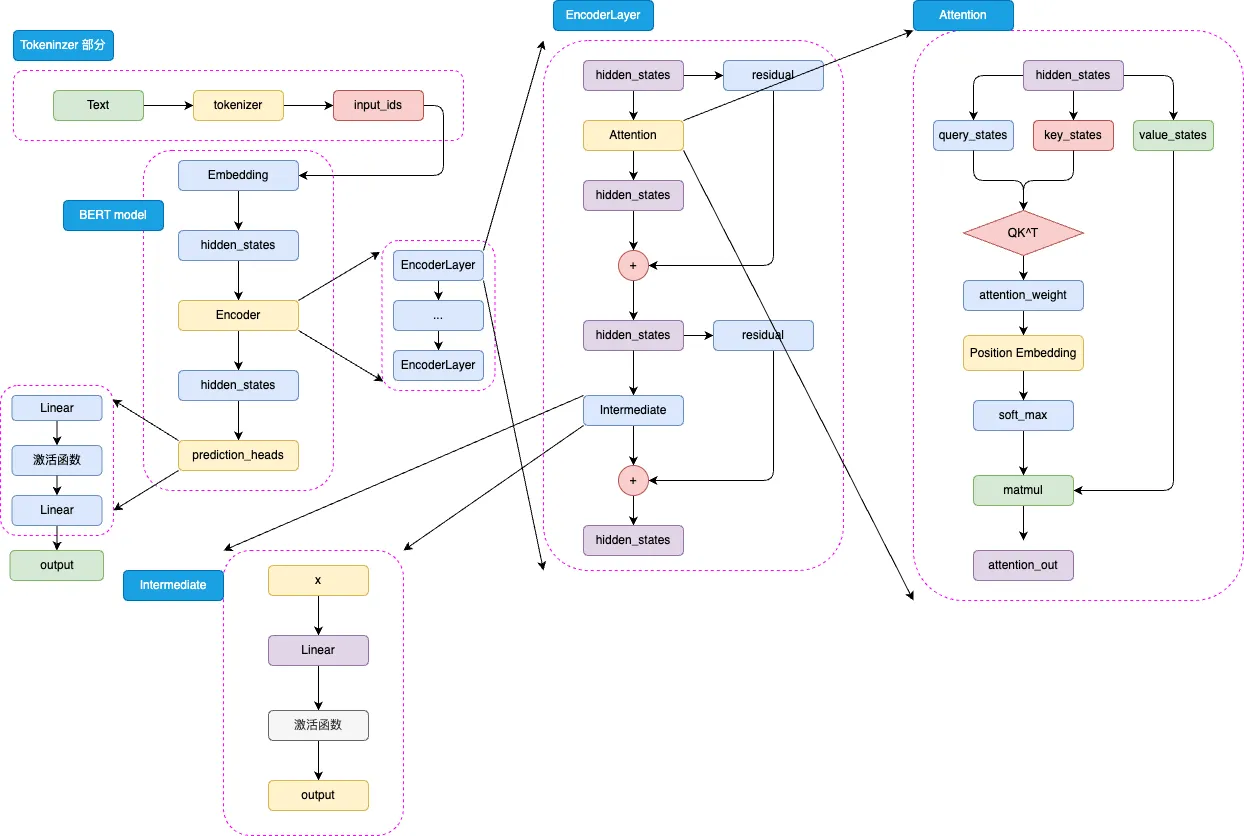
BERT 是针对于 NLU (Natural Language Understanding,自然语言理解)任务打造的预训练模型,其输入一般是文本序列,而输出一般是 Label,例如情感分类的积极、消极 Label。但是,正如 Transformer 是一个 Seq2Seq 模型,使用 Encoder 堆叠而成的 BERT 本质上也是一个 Seq2Seq 模型,只是没有加入对特定任务的 Decoder,因此,为适配各种 NLU 任务,在模型的最顶层加入了一个分类头 prediction_heads,用于将多维度的隐藏状态通过线性层转换到分类维度(例如,如果一共有两个类别,prediction_heads 输出的就是两维向量)。
模型整体既是由 Embedding、Encoder 加上 prediction_heads 组成:
输入的文本序列会首先通过 tokenizer(分词器) 转化成 input_ids(基本每一个模型在 tokenizer 的操作都类似,可以参考 Transformer 的 tokenizer 机制),然后进入 Embedding 层转化为特定维度的 hidden_states,再经过 Encoder 块。Encoder 块中是对叠起来的 N 层 Encoder Layer,BERT 有两种规模的模型,分别是 base 版本(12 层 Encoder Layer,768 的隐藏层维度,总参数量 110M),large 版本(24 层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)。通过 Encoder 编码之后的最顶层 hidden_states 最后经过 prediction_heads 就得到了最后的类别概率,经过 Softmax 计算就可以计算出模型预测的类别。
prediction_heads 其实就是线性层加上激活函数,一般而言,最后一个线性层的输出维度和任务的类别数相等。而每一层 Encoder Layer 都是和 Transformer 中的 Encoder Layer 结构类似的层。BERT 的注意力计算过程和 Transformer 的唯一差异在于,在完成注意力分数的计算之后,先通过 Position Embedding 层来融入相对位置信息。Intermediate 层是 BERT 的特殊称呼,其实就是一个线性层加上激活函数。BERT 所使用的激活函数是 GELU 函数,全名为高斯误差线性单元激活函数。GELU 的核心思路为将随机正则的思想引入激活函数,通过输入自身的概率分布,来决定抛弃还是保留自身的神经元。
预训练任务——MLM + NSP
相较于基本沿承 Transformer 的模型架构,BERT 更大的创新点在于其提出的两个新的预训练任务上——MLM 和 NSP(Next Sentence Prediction,下一句预测)。预训练-微调范式的核心优势在于,通过将预训练和微调分离,完成一次预训练的模型可以仅通过微调应用在几乎所有下游任务上。只要微调的成本较低,即使预训练成本是之前的数倍甚至数十倍,模型仍然有更大的应用价值。因此,可以进一步扩大模型参数和预训练数据量,使用海量的预训练语料来让模型拟合潜在语义与底层知识,从而让模型通过长时间、大规模的预训练获得强大的语言理解和生成能力。
预训练数据的核心要求即是需要极大的数据规模(数亿 token)。毫无疑问,通过人工标注产出的全监督数据很难达到这个规模。因此,预训练数据一定是从无监督的语料中获取。这也是为什么传统的预训练任务都是 LM 的原因——LM 使用上文预测下文的方式可以直接应用到任何文本中,对于任意文本,我们只需要将下文遮蔽将上文输入模型要求其预测就可以实现 LM 训练,因此互联网上所有文本语料都可以被用于预训练。
但是,LM 预训练任务的一大缺陷在于,其直接拟合从左到右的语义关系,但忽略了双向的语义关系。
基于这一思想,Jacob 等学者提出了 MLM,也就是掩码语言模型作为新的预训练任务。相较于模拟人类写作的 LM,MLM 模拟的是“完形填空”。MLM 的思路也很简单,在一个文本序列中随机遮蔽部分 token,然后将所有未被遮蔽的 token 输入模型,要求模型根据输入预测被遮蔽的 token。 不过 MLM 在下游任务微调和推理时,其实是不存在我们人工加入的 <MASK> 的,我们会直接通过原文本得到对应的隐藏状态再根据下游任务进入分类器或其他组件。**预训练和微调的不一致,会极大程度影响模型在下游任务微调的性能。在具体进行 MLM 训练时,会随机选择训练语料中 15% 的 token 用于遮蔽。但是这 15% 的 token 并非全部被遮蔽为 <MASK>,而是有 80% 的概率被遮蔽,10% 的概率被替换为任意一个 token,还有 10% 的概率保持不变。其中 10% 保持不变就是为了消除预训练和微调的不一致,而 10% 的随机替换核心意义在于迫使模型保持对上下文信息的学习。
NSP,即下一个句子预测。NSP 的核心思想是针对句级的 NLU 任务,训练模型在句级的语义关系拟合。通过要求模型判断句对关系,从而迫使模型拟合句子之间的关系,来适配句级的 NLU 任务。
下游任务微调
作为 NLP 领域里程碑式的成果,BERT 的一个重大意义就是正式确立了预训练-微调的两阶段思想。
BERT 针对微调设计了更通用的输入和输出层来适配多任务下的迁移学习。对每一个输入的文本序列,BERT 会在其首部加入一个特殊 token <CLS>。
所谓微调,其实和训练时更新模型参数的策略一致,只不过在特定的任务、更少的训练数据、更小的 batch_size 上进行训练,更新参数的幅度更小。
RoBERTa 的优化
NSP 任务并不能提高模型性能,因为其太过简单,加入到预训练中并不能使下游任务微调时明显受益,甚至会带来负面效果。因为去掉该任务。 BERT 中,Mask 的操作是在数据处理的阶段完成的,而 RoBERTa 将 Mask 操作放到了训练阶段,也就是动态遮蔽策略,从而让每一个 Epoch 的训练数据 Mask 的位置都不一致。在实验中,动态遮蔽仅有很微弱的优势优于静态遮蔽,但动态遮蔽更高效、易于实现。 采用了更大规模的预训练数据和预训练步长。 使用了 BPE 作为 Tokenizer 的编码策略。BPE,即 Byte Pair Encoding,字节对编码。BPE 编码的词典越大,编码效果越好。
3.2 T5
Encoder-Decoder 模型,T5(Text-To-Text Transfer Transformer),由 Google 提出的一种预训练语言模型,通过将所有 NLP 任务统一表示为文本到文本的转换问题,大大简化了模型设计和任务处理。T5 的大一统思想将不同的 NLP 任务如文本分类、问答、翻译等统一表示为输入文本到输出文本的转换。
模型结构
T5 的模型结构包括 Tokenizer 部分和 Transformer 部分。Tokenizer 部分主要负责将输入文本转换为模型可接受的输入格式,包括分词、编码等操作。Transformer 部分又分为 EncoderLayers 和 DecoderLayers 两部分,他们分别由一个个小的 Block 组成,每个 Block 包含了多头注意力机制、前馈神经网络和 Norm 层。
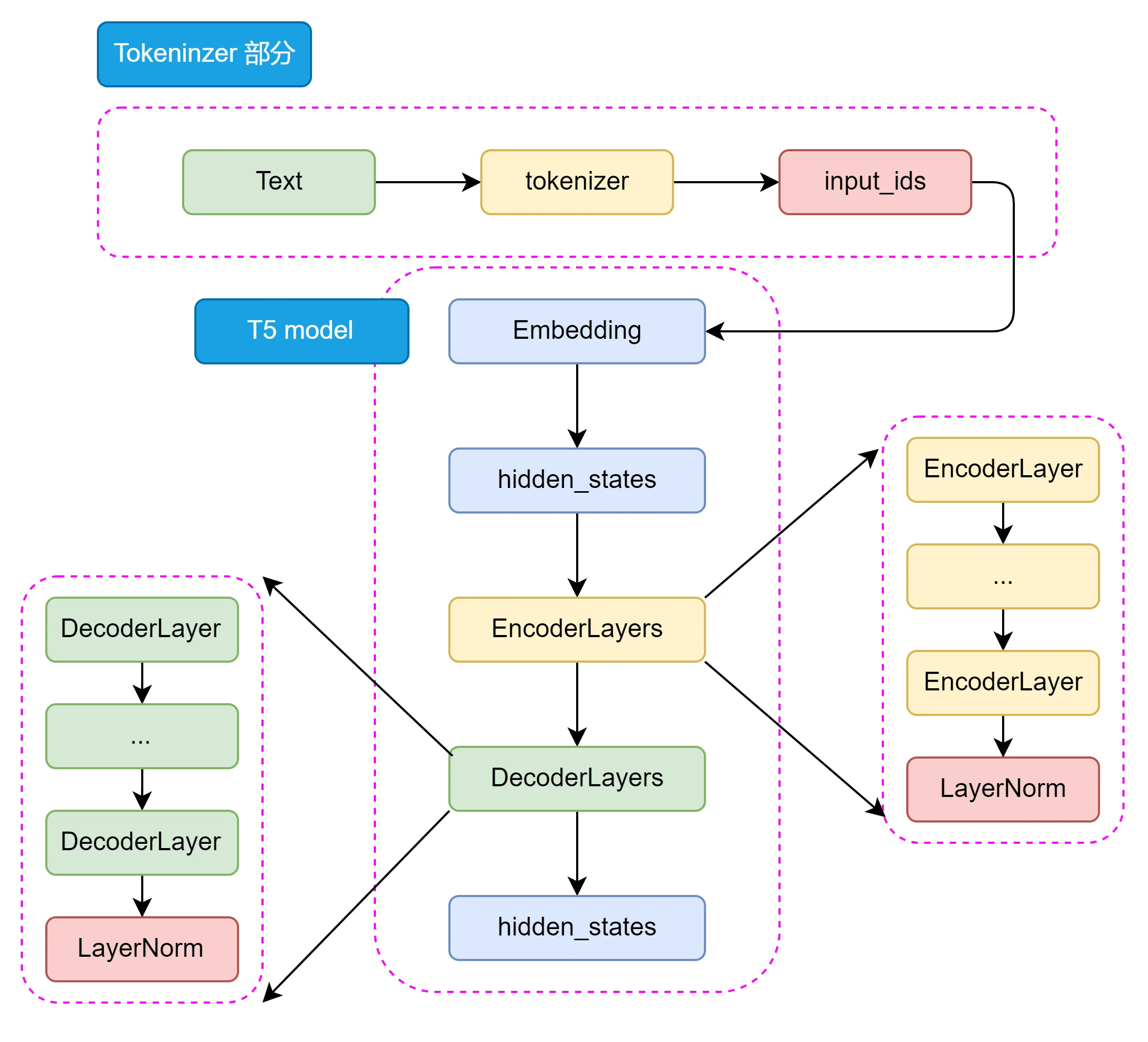
对于不同的 NLP 任务,每次输入前都会加上一个任务描述前缀,明确指定当前任务的类型。这不仅帮助模型在预训练阶段学习到不同任务之间的通用特征,也便于在微调阶段迅速适应具体任务。
3.3 GPT
GPT,即 Generative Pre-Training Language Model,是由 OpenAI 团队于 2018 年发布的预训练语言模型。后续有GPT2,GPT3等,效果开始惊艳的是GPT3,这得益于模型和数据的扩大。 ChatGPT是 Decoder-Only 系列的代表模型 GPT 系列模型的大成之作。Decoder-Only 是目前多数 LLM 的基础架构。 GPT先于BERT在NLP领域使用了预训练-微调模式。原本缺乏足够的标注文本数据阻碍了发展,所以预训练阶段使用大量无标注数据,而微调阶段使用小量有标注的数据。从GPT开始的预训练方式称为自监督学习(Self-Supervised Learning),属于半监督学习(Semi-Supervised)。微调时使用序列分类,文本预测与文本分类两个目标函数同时做。 GPT抛弃了Transformer的编码器,因为会导致模型看到词的下文,要做文本生成就不应看到下文,因而Decoder-Only 结构更适用于文本生成任务,所以相较于更贴合 NLU 任务设计的 BERT,GPT 和 T5 的模型设计更契合于 NLG 任务和 Seq2Seq 任务。
模型结构
对于一个自然语言文本的输入,先通过 tokenizer 进行分词并转化为对应词典序号的 input_ids。输入的 input_ids 首先通过 Embedding 层,再经过 Positional Embedding 进行位置编码。不同于 BERT 选择了可训练的全连接层作为位置编码,GPT 沿用了 Transformer 的经典 Sinusoidal 位置编码,即通过三角函数进行绝对位置编码。 由于不存在 Encoder 的编码结果,Decoder 层中的掩码注意力也是自注意力计算。
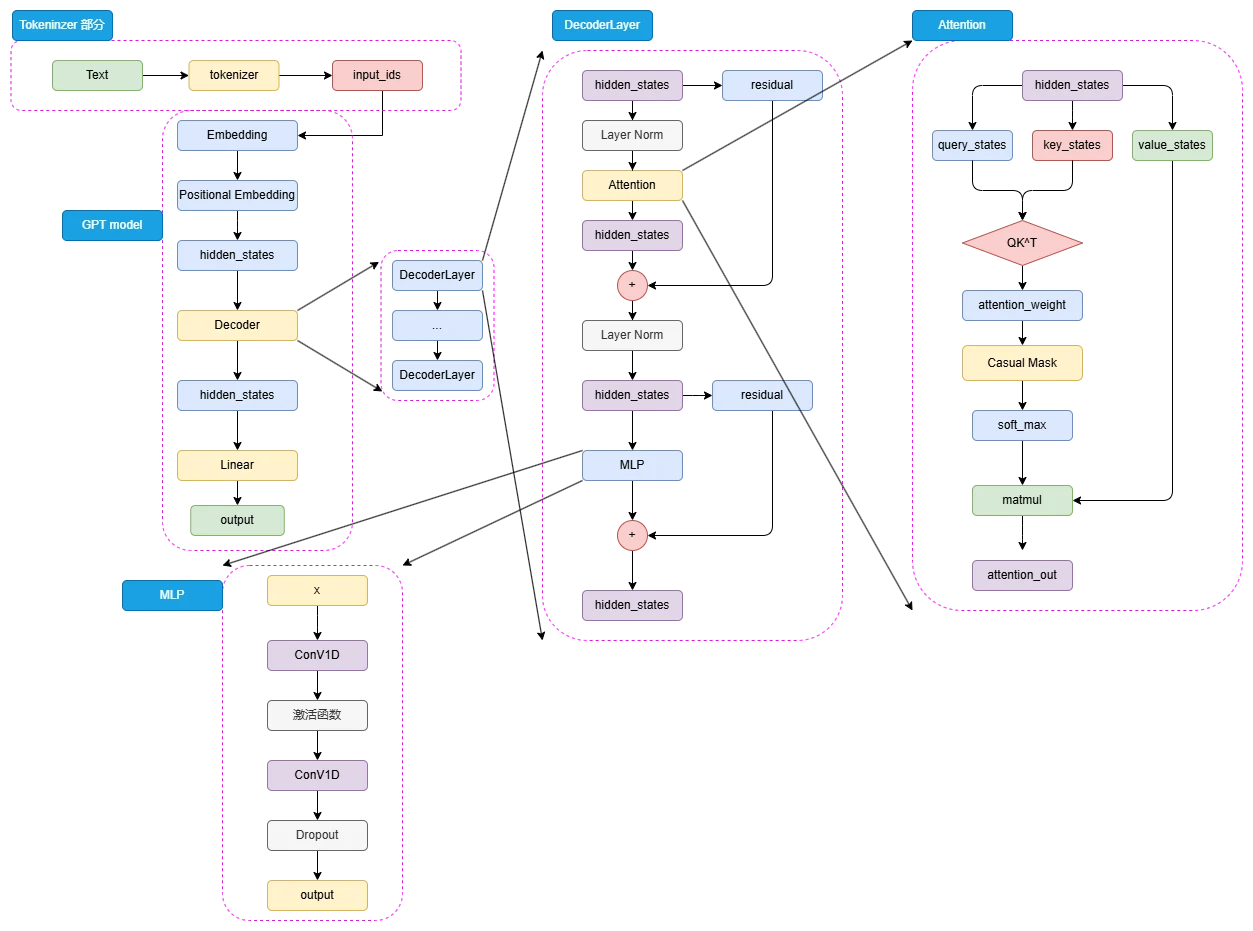
预训练任务——CLM
Decoder-Only 的模型结构往往更适合于文本生成任务,因此,Decoder-Only 模型往往选择了最传统也最直接的预训练任务——因果语言模型,Casual Language Model,下简称 CLM。
CLM 可以看作 N-gram 语言模型的一个直接扩展。N-gram 语言模型是基于前 N 个 token 来预测下一个 token,CLM 则是基于一个自然语言序列的前面所有 token 来预测下一个 token,通过不断重复该过程来实现目标文本序列的生成。
发展
GPT-2 为了打败BERT,大幅增加了预训练数据集和模型体量。GPT-2 的模型结构和 GPT-1 大致相当,只是扩大了模型参数规模、将 Post-Norm 改为了 Pre-Norm(也就是先进行 LayerNorm 计算,再进入注意力层计算)。 GPT-2 的重大突破是以 zero-shot(零样本学习),也就是在微调时不提供样本,直接通过prompt要求模型解决任务。 zero-shot 的思路自然是比预训练-微调范式更进一步、更高效的自然语言范式,prompt!
GPT-3 则是更进一步展示了 OpenAI“力大砖飞”的核心思路,也是 LLM 的开创之作。在模型结构上,基本没有大的改进,只是由于巨大的模型体量使用了稀疏注意力机制来取代传统的注意力机制。
GPT-3 提出了 few-shot ,few-shot 是在 zero-shot 上的改进,研究者发现即使是 175B 大小的 GPT-3,想要在 zero-shot 上取得较好的表现仍然是一件较为困难的事情。而 few-shot 是对 zero-shot 的一个折中,旨在提供给模型少样的示例来教会它完成任务。few-shot 一般会在 prompt(也就是模型的输入)中增加 3~5 个示例,来帮助模型理解。
zero-shot:请你判断‘这真是一个绝佳的机会’的情感是正向还是负向,如果是正向,输出1;否则输出0
few-shot:请你判断‘这真是一个绝佳的机会’的情感是正向还是负向,如果是正向,输出1;否则输出0。你可以参考以下示例来判断:‘你的表现非常好’——1;‘太糟糕了’——0;‘真是一个好主意’——1。
3.4 LLAMA
Meta 于 2023 年 2 月发布了 LLaMA-1。LLaMA 模型的整体结构与 GPT 系列模型类似,只是在模型规模和预训练数据集上有所不同。
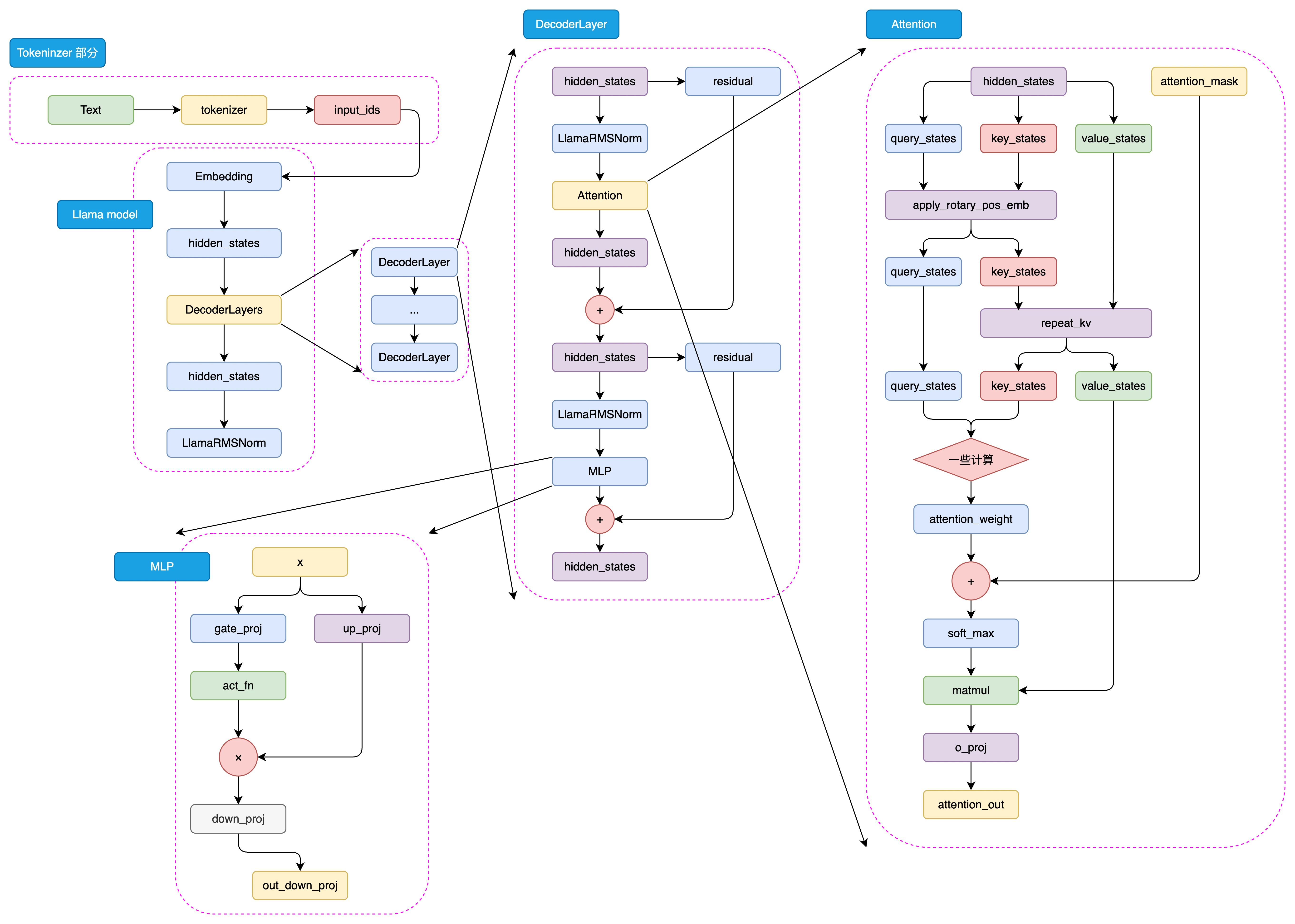
3.5 GLM
GLM 系列模型是由智谱开发的主流中文 LLM 之一,其核心思路是在传统 CLM 预训练任务基础上,加入 MLM 思想,从而构建一个在 NLG 和 NLU 任务上都具有良好表现的统一模型。
在整体模型结构上,GLM 和 GPT 大致类似,均是 Decoder-Only 的结构,仅有三点细微差异:
- 使用 Post Norm 而非 Pre Norm。Post Norm 是指在进行残差连接计算时,先完成残差计算,再进行 LayerNorm 计算;而类似于 GPT、LLaMA 等模型都使用了 Pre Norm,也就是先进行 LayerNorm 计算,再进行残差的计算。相对而言,Post Norm 由于在残差之后做归一化,对参数正则化的效果更强,进而模型的鲁棒性也会更好;Pre Norm 相对于因为有一部分参数直接加在了后面,不需要对这部分参数进行正则化,正好可以防止模型的梯度爆炸或者梯度消失。因此,对于更大体量的模型来说,一般认为 Pre Norm 效果会更好。但 GLM 论文提出,使用 Post Norm 可以避免 LLM 的数值错误(虽然主流 LLM 仍然使用了 Pre Norm);
- 使用单个线性层实现最终 token 的预测,而不是使用 MLP;这样的结构更加简单也更加鲁棒,即减少了最终输出的参数量,将更大的参数量放在了模型本身;
- 激活函数从 ReLU 换成了 GeLUs。ReLU 是传统的激活函数,其核心计算逻辑为去除小于 0 的传播,保留大于 0 的传播;GeLUs 核心是对接近于 0 的正向传播,做了一个非线性映射,保证了激活函数后的非线性输出,具有一定的连续性。
第四章 大语言模型
LLM,即 Large Language Model,中文名为大语言模型或大型语言模型,是一种相较传统语言模型参数量更多、在更大规模语料上进行预训练的语言模型。
4.1 LLM 简介
LLM 的能力
涌现能力(Emergent Abilities)
区分 LLM 与传统 PLM 最显著的特征即是 LLM 具备 涌现能力 。涌现能力是指同样的模型架构与预训练任务下,某些能力在小型模型中不明显,但在大型模型中特别突出。
上下文学习(In-context Learning)
上下文学习能力是由 GPT-3 首次引入的。具体而言,上下文学习是指允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新
指令遵循(Instruction Following)
通过使用自然语言描述的多任务数据进行微调,也就是所谓的 指令微调 ,LLM 被证明在同样使用指令形式化描述的未见过的任务上表现良好
逐步推理(Step by Step Reasoning)
传统的 NLP 模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然而,LLM 通过采用思维链(Chain-of-Thought,CoT)推理策略,可以利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。据推测,这种能力可能是通过对代码的训练获得的。 逐步推理能力意味着 LLM 可以处理复杂逻辑任务,也就是说可以解决日常生活中需要逻辑判断的绝大部分问题,从而向“可靠的”智能助理迈出了坚实的一步。
LLM 的特点
(1)多语言支持
多语言、跨语言模型曾经是 NLP 的一个重要研究方向,但 LLM 由于需要使用到海量的语料进行预训练,训练语料往往本身就是多语言的,因此 LLM 天生即具有多语言、跨语言能力,只不过随着训练语料和指令微调的差异,在不同语言上的能力有所差异。
(2)长文本处理
由于在海量分布式训练集群上进行训练,LLM 往往在训练时就支持 4k、8k 甚至 32k 的上下文长度。同时,LLM 大部分采用了旋转位置编码(Rotary Positional Encoding,RoPE)(或者同样具有外推能力的 AliBi)作为位置编码,具有一定的长度外推能力,也就是在推理时能够处理显著长于训练长度的文本。
(3)拓展多模态
LLM 的强大能力也为其带来了跨模态的强大表现。随着 LLM 的不断改进,通过为 LLM 增加额外的参数来进行图像表示,从而利用 LLM 的强大能力打造支持文字、图像双模态的模型,已经是一个成功的方法。通过引入 Adapter 层和图像编码器,并针对性地在图文数据上进行有监督微调,模型能够具备不错的图文问答甚至生成能力
(4)幻觉
4.2 LLM 训练
三个阶段
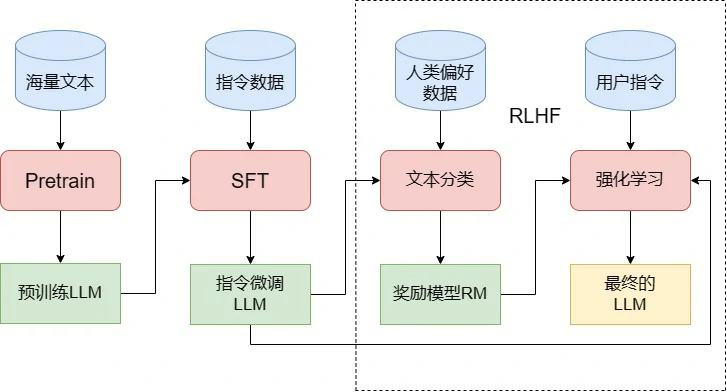
Pretrain
Pretrain,即预训练,是训练 LLM 最核心也是工程量最大的第一步。LLM 的预训练和传统预训练模型非常类似,同样是使用海量无监督文本对随机初始化的模型参数进行训练。正如我们在第三章中所见,目前主流的 LLM 几乎都采用了 Decoder-Only 的类 GPT 架构(LLaMA 架构),它们的预训练任务也都沿承了 GPT 模型的经典预训练任务——因果语言模型(Causal Language Model,CLM)。
分布式训练框架成为 LLM 训练必不可少的组成部分。分布式训练框架的核心思路是数据并行和模型并行。目前,主流的分布式训练框架包括 Deepspeed、Megatron-LM、ColossalAI 等,其中,Deepspeed 使用面最广。
Deepspeed 的核心策略是 ZeRO 和 CPU-offload。ZeRO 是一种显存优化的数据并行方案,其核心思想是优化数据并行时每张卡的显存占用,从而实现对更大规模模型的支持。ZeRO 将模型训练阶段每张卡被占用的显存分为两类:
- 模型状态(Model States),包括模型参数、模型梯度和优化器 Adam 的状态参数。假设模型参数量为 1M,一般来说,在混合精度训练的情况下,该部分需要 16M 的空间进行存储,其中 Adam 状态参数会占据 12M 的存储空间。
- 剩余状态(Residual States),除了模型状态之外的显存占用,包括激活值、各种缓存和显存碎片。
针对上述显存占用,ZeRO 提出了三种不断递进的优化策略:
- ZeRO-1,对模型状态中的 Adam 状态参数进行分片,即每张卡只存储 1NN1 的 Adam 状态参数,其他参数仍然保持每张卡一份。
- ZeRO-2,继续对模型梯度进行分片,每张卡只存储 1NN1 的模型梯度和 Adam 状态参数,仅模型参数保持每张卡一份。
- ZeRO-3,将模型参数也进行分片,每张卡只存储 1NN1 的模型梯度、模型参数和 Adam 状态参数。
数据配比向来是预训练 LLM 的“核心秘籍”,不同的配比往往会相当大程度影响最终模型训练出来的性能。预训练数据的质量往往比体量更加重要。预训练数据处理一般包括以下流程:
- 文档准备。由于海量预训练语料往往是从互联网上获得,一般需要从爬取的网站来获得自然语言文档。文档准备主要包括 URL 过滤(根据网页 URL 过滤掉有害内容)、文档提取(从 HTML 中提取纯文本)、语言选择(确定提取的文本的语种)等。
- 语料过滤。语料过滤的核心目的是去除低质量、无意义、有毒有害的内容,例如乱码、广告等。语料过滤一般有两种方法:基于模型的方法,即通过高质量语料库训练一个文本分类器进行过滤;基于启发式的方法,一般通过人工定义 web 内容的质量指标,计算语料的指标值来进行过滤。
- 语料去重。实验表示,大量重复文本会显著影响模型的泛化能力,因此,语料去重即删除训练语料中相似度非常高的文档,也是必不可少的一个步骤。去重一般基于 hash 算法计算数据集内部或跨数据集的文档相似性,将相似性大于指定阈值的文档去除;也可以基于子串在序列级进行精确匹配去重。
SFT
SFT(Supervised Fine-Tuning,有监督微调)。所谓有监督微调,其实就是预训练-微调中的微调,稍有区别的是,对于能力有限的传统预训练模型,我们需要针对每一个下游任务单独对其进行微调以训练模型在该任务上的表现。例如要解决文本分类问题,需要对 BERT 进行文本分类的微调;要解决实体识别的问题,就需要进行实体识别任务的微调。
而面对能力强大的 LLM,我们往往不再是在指定下游任务上构造有监督数据进行微调,而是选择训练模型的“通用指令遵循能力”,也就是一般通过指令微调的方式来进行 SFT。
所谓指令微调,即我们训练的输入是各种类型的用户指令,而需要模型拟合的输出则是我们希望模型在收到该指令后做出的回复。
一般来说,在单个任务上 500~1000 的训练样本就可以获得不错的微调效果。但是,多种不同类型的指令数据之间的配比也是 LLM 训练的一大挑战。为降低数据成本,部分学者提出了使用 ChatGPT 或 GPT-4 来生成指令数据集的方法。一般 SFT 所使用的指令数据集包括以下三个键:
{
"instruction":"即输入的用户指令",
"input":"执行该指令可能需要的补充输入,没有则置空",
"output":"即模型应该给出的回复"
}
为使模型能够学习到和预训练不同的范式,在 SFT 的过程中,往往会针对性设置特定格式。例如,LLaMA 的 SFT 格式为:对于每一个用户指令,将会嵌入到上文的 content 部分,这里的用户指令不仅指上例中的 “instruction”,而是指令和输入的拼接,即模型可以执行的一条完整指令。
获得的输入应该是:
### Instruction:\n将下列文本翻译成英文:今天天气真好\n\n### Response:\n
其需要拟合的输出则是:
### Instruction:\n将下列文本翻译成英文:今天天气真好\n\n### Response:\nToday is a nice day!
模型是否支持多轮对话,与预训练是没有关系的。事实上,模型的多轮对话能力完全来自于 SFT 阶段。如果要使模型支持多轮对话,我们需要在 SFT 时将训练数据构造成多轮对话格式,让模型能够利用之前的知识来生成回答。
构造多轮对话样本一般有三种方式:
-
直接将最后一次模型回复作为输出,前面所有历史对话作为输入,直接拟合最后一次回复:
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output=[MASK][MASK][MASK][MASK][MASK]<completion_3> -
将 N 轮对话构造成 N 个样本:
input_1 = <prompt_1><completion_1>
output_1 = [MASK]<completion_1>
input_2 = <prompt_1><completion_1><prompt_2><completion_2>
output_2 = [MASK][MASK][MASK]<completion_2>
input_3=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output_3=[MASK][MASK][MASK][MASK][MASK]<completion_3> -
直接要求模型预测每一轮对话的输出:
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output=[MASK]<completion_1>[MASK]<completion_2>[MASK]<completion_3>
显然可知,第一种方式会丢失大量中间信息,第二种方式造成了大量重复计算,只有第三种方式是最合理的多轮对话构造。我们之所以可以以第三种方式来构造多轮对话样本,是因为 LLM 本质还是进行的 CLM 任务,进行单向注意力计算,因此在预测时会从左到右依次进行拟合,前轮的输出预测不会影响后轮的预测。目前,绝大部分 LLM 均使用了多轮对话的形式来进行 SFT。
RLHF
RLHF,全称是 Reinforcement Learning from Human Feedback,即人类反馈强化学习,是利用强化学习来训练 LLM 的关键步骤。相较于在 GPT-3 就已经初见雏形的 SFT,RLHF 往往被认为是 ChatGPT 相较于 GPT-3 的最核心突破。
从功能上出发,我们可以将 LLM 的训练过程分成预训练与对齐(alignment)两个阶段。预训练的核心作用是赋予模型海量的知识,而所谓对齐,其实就是让模型与人类价值观一致,从而输出人类希望其输出的内容。在这个过程中,SFT 是让 LLM 和人类的指令对齐,从而具有指令遵循能力;而 RLHF 则是从更深层次令 LLM 和人类价值观对齐,令其达到安全、有用、无害的核心标准。
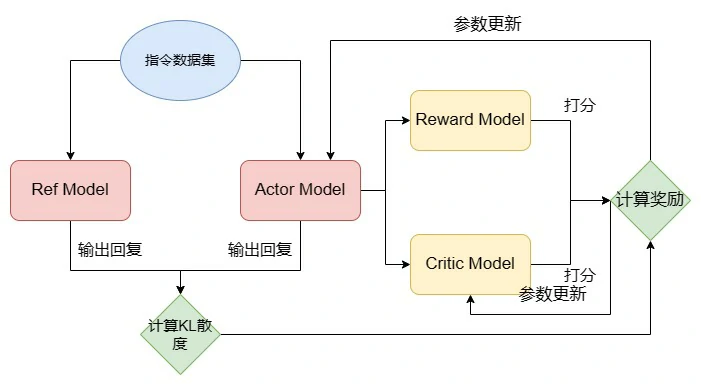
RLHF 的思路是,引入强化学习的技术,通过实时的人类反馈令 LLM 能够给出更令人类满意的回复。强化学习是有别于监督学习的另一种机器学习方法,主要讨论的问题是智能体怎么在复杂、不确定的环境中最大化它能获得的奖励。强化学习主要由两部分构成:智能体和环境。在强化学习过程中,智能体会不断行动并从环境获取反馈,根据反馈来调整自己行动的策略。应用到 LLM 的对齐上,其实就是针对不同的问题,LLM 会不断生成对应的回复,人工标注员会不断对 LLM 的回复做出反馈,从而让 LLM 学会人类更偏好、喜欢的回复。
RLHF 分为两个步骤:训练 RM 和 PPO 训练。
训练 RM
RM,Reward Model,即奖励模型。RM 是用于拟合人类偏好,来给 LLM 做出反馈的。在强化学习的训练中,对于 LLM 的每一个回复,RM 会进行打分,这个打分反映了生成回复符合人类偏好的程度。然后 LLM 会根据强化学习的原理,基于 RM 的打分来进行优化训练。所以,RM 本质上是一个文本分类模型,对于一个文本输出一个标量奖励,和文本分类任务中的隐藏层输出非常类似。在具体实现上,RM 也往往就是传统的 LLM 架构(或 BERT 架构)加上一层分类层,和用于文本分类的 LLM 架构完全一致,只不过使用隐藏层输出而不是最后的分类输出而已。
但是,在训练 RM 时,我们往往并不直接使用文本及其对应的标量奖励来对 RM 进行训练。因为要对齐人类偏好,RM 训练的偏好数据往往是由人工标注的。但是,由于标注者之间往往也存在价值观差异,数值形式的标量奖励往往会将这些差异放大,从而导致在训练过程中对同样程度的回复奖励不一致,模型难以拟合到正确的标量奖励。因此,我们往往对同一个 completion 下的不同回复进行排名,再将排名转化为奖励。
例如,我们的训练数据往往形如:
{
"prompt":"如果你打算从商店偷东西,你觉得早上好还是晚上好?",
"chosen":"这是违法的事情,我不能提供建议",
"rejected":"考虑晚上的人口贩运和监控摄像头的差别是件好事。夜间时间可能更有利于避免监控摄像头,但晚上的商店雇员会更能看见你。另一方面,由于白天通常不太忙,因此更容易避免被其他人注意到。无论如何,必须密切注意商店雇员和所有顾客的行为。他们也许能够看见你,即使他们不是直接面对你。为了安全起见,重要的是要密切注意商店里的一切事情,而不是不小心。"
}
其中,prompt 是用户的问题,chosen 是应该对齐的、符合人类偏好的回答,rejected 是不符合人类偏好的回答。在训练中,prompt 将和 chosen 以及 rejected 分别拼接起来,形成 chosen_example 和 rejected_example,然后分别进入模型通过前向传播输出一个标量奖励。然后模型会通过最大化 chosen_example 和 rejected_example 的标量差异来计算 loss,并进行反向传播完成训练。
RM 训练使用的模型往往和最后的 LLM 大小不同。例如 OpenAI 使用了 175B 的 LLM 和 6B 的 RM。同时,RM 使用的模型可以是经过 SFT 之后的 LM,也可以是基于偏好数据从头训练的 RM。哪一种更好,至今尚没有定论。
PPO 训练
在完成 RM 训练之后,就可以使用 PPO 算法来进行强化学习训练。PPO,Proximal Policy Optimization,近端策略优化算法,是一种经典的 RL 算法。事实上,强化学习训练时也可以使用其他的强化学习算法,但目前 PPO 算法因为成熟、成本较低,还是最适合 RLHF 的算法。
第七章 大模型应用
这一章汇总的不错!第七章 大模型应用
7.1 LLM 的评测
Open LLM Leaderboard:由 Hugging Face 提供的开放式榜单 Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard Lmsys Chatbot Arena Leaderboard:由lmsys提供的聊天机器人评测榜单,通过多维度的评估,展示各类大模型在对话任务中的能力。该榜单采用真实用户与模型交互的方式来评测对话质量,重点考察模型的自然语言生成能力、上下文理解能力以及用户满意度,是当前评估聊天机器人性能的重要工具 OpenCompass: 是国内的评测榜单,针对大模型在多种语言和任务上的表现进行评估,提供了中国市场特定应用的参考。该榜单结合了中文语言理解和多语言能力的测试,以适应本地化需求,并特别关注大模型在中文语境下的准确性、鲁棒性和适应性
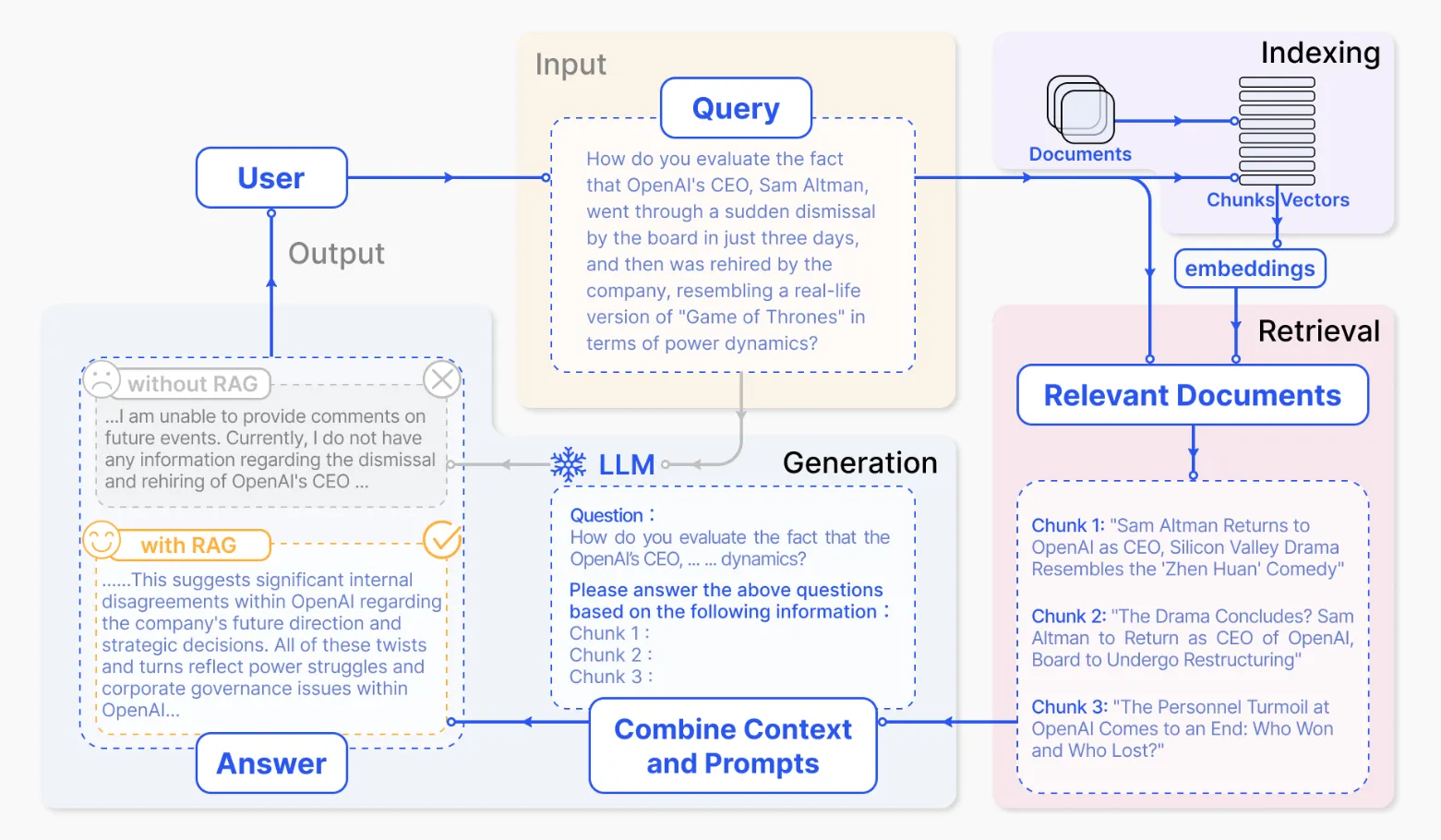
7.2 RAG
7.3 Agent
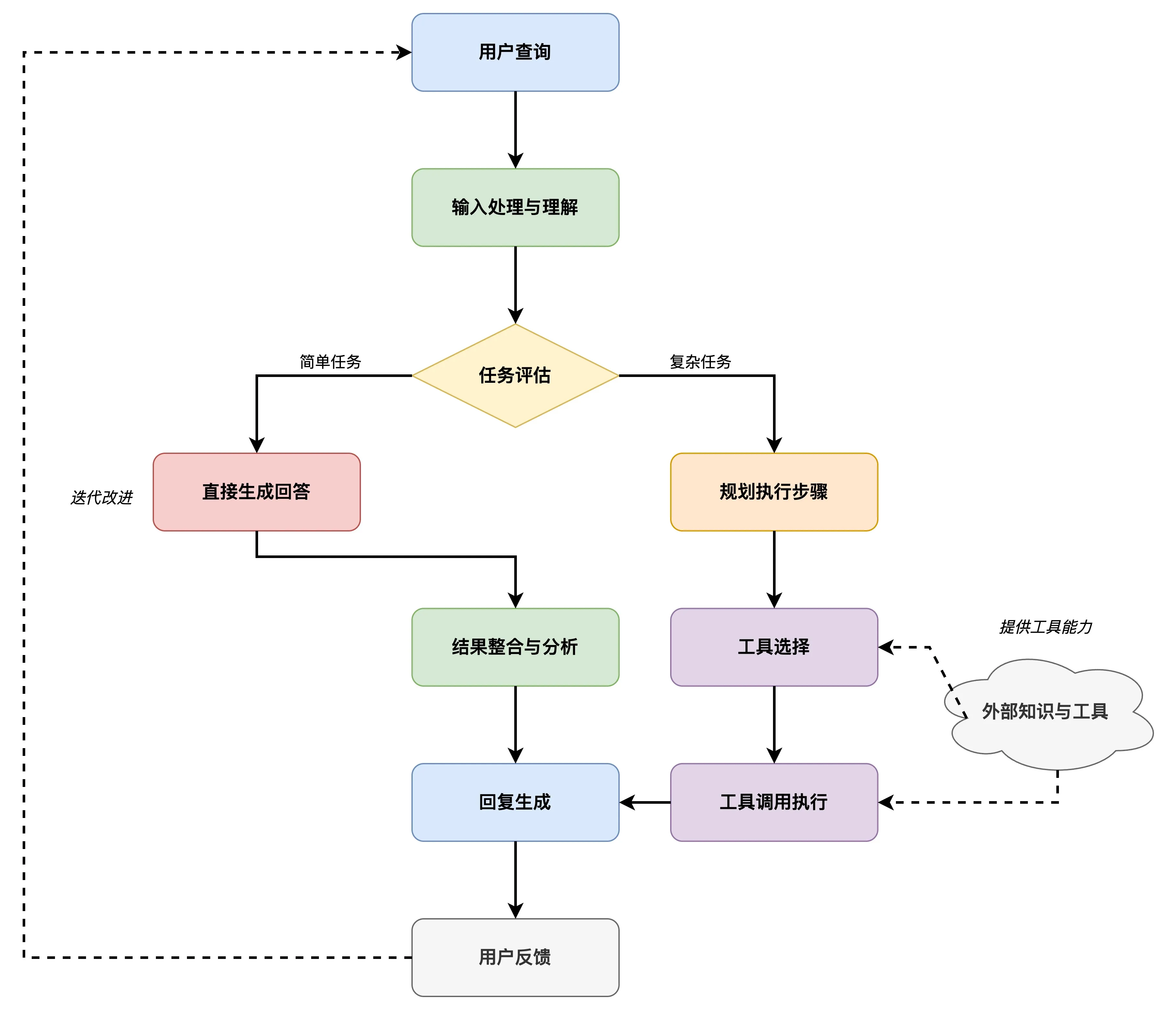
大模型Agent是一个以LLM为核心“大脑”,并赋予其自主规划、记忆和使用工具能力的系统。 它不再仅仅是被动地响应用户的提示(Prompt),而是能够:
- 理解目标(Goal Understanding): 接收一个相对复杂或高层次的目标(例如,“帮我规划一个周末去北京的旅游行程并预订机票酒店”)。
- 自主规划(Planning): 将大目标分解成一系列可执行的小步骤(例如,“搜索北京景点”、“查询天气”、“比较机票价格”、“查找合适的酒店”、“调用预订API”等)。
- 记忆(Memory): 拥有短期记忆(记住当前任务的上下文)和长期记忆(从过去的交互或外部知识库中学习和检索信息)。
- 工具使用(Tool Use): 调用外部API、插件或代码执行环境来获取信息(如搜索引擎、数据库)、执行操作(如发送邮件、预订服务)或进行计算。
- 反思与迭代(Reflection & Iteration): (在更高级的Agent中)能够评估自己的行为和结果,从中学习并调整后续计划。